Interviewing IoT Experts on Sensor Metadata
September 10, 2020 | Josué Kpodo
Difficult as it is to believe, we have reached the end of the summer and the end of Josué Kpodo's time with us as an intern. In this post, Josué provides a final update on his work gathering user needs and prior art to inform the creation of the TC53 Sensor Data Provenance Specification draft.
>
Working with Josué this summer has been a pleasure. He has provided a welcome additional voice in the TC53 drafting process and an enthusiasm for learning new skills that has shown brightly through this challenging summer. The Moddable team looks forward to following his career in agricultural IoT!
>
> - Andy Carle
Introduction
In my previous blog post, I shared my first exposure to embedded systems development with the Moddable SDK. I also touched on my plan for interviewing stakeholders to inform the design of the TC53 sensor provenance API. In this blog, I will share my journey from conducting those interviews, to synthesizing the findings, and finally participating in drafting an API specification. I will also provide context on existing APIs and frameworks which offer functional solutions to similar problems (e.g. data accuracy and recording sensor configurations) as those TC53 is trying to solve. I will explain why studying this existing work, such as OGC Sensor Web Standards and GS1 barcodes, could inspire TC53 and offer a strong starting point for writing the specification of the sensor provenance API and inform initial implementations.
Sensor Metadata Stakeholder Interviews
Identifying Stakeholders
TC53 is drafting a sensor metadata API to benefit stakeholders and end-users with the following profiles:
- high-level embedded application developers
- cloud application developers
- data scientists working with sensors
My work was to find people who matched these profiles and interview them. Thanks to both the Moddable team and my network at Michigan State University, I was able to locate potential interview participants with diverse backgrounds, but a shared interest in sensor data. For example, I interviewed researchers studying computer vision and object detection; engineers building autonomous systems and robots; JavaScript platform/framework developers; IoT enthusiasts/hobbyists; and scientists developing advanced weather stations for regional and international deployment.
Consequently, our stakeholders work with and gather data from many types of sensors: lidars, radars, digital cameras, IMUs, environmental sensors, and even scanning electron microscopes, just to name a few.
Interview Protocol
The interviews were one-on-one and took place remotely. The questions were designed to be open-ended and non-assumptive. For example, stakeholders were asked:
- What sensor data and metadata do they collect?
- What level of detail do they record about the source of that data?
- How accurate do these data need to be for the overall information to be useful?
Parsing of Interview Results
Due to the diverse background of our stakeholders, the findings of my interviews were quite disparate. The resulting challenge was to incorporate the uniqueness of some stakeholders' needs into the scope of TC53's present work: the creation of a lightweight metadata API for expressing sensor data provenance that builds on top of the Sensor Class Pattern.
Another challenge was to group the dataset of metadata findings into categories that accurately represent the whole set. In consultation with my project advisors, I decided that the affinity diagramming tool was appropriate for the task. An affinity diagram is an analytical, inductive, and visual tool that is useful for revealing hidden associations and patterns to reveal latent themes among disconnected information (e.g. field interviews).
1. Finding the Categories
Parsing the interview findings was a long and iterative process. The first step was to determine the main categories. It took fifteen iterations of filtering the metadata before grouping them into appropriate categories.
At first, similar findings were grouped into similar buckets. For example, "time of device calibration", "timezone", "time of data capture" were grouped under the "time" bucket. The next filtering pass involved the linking of two separate findings. For example, the surrounding temperature may affect the sensor sensitivity. Therefore "surrounding temperature" and "sensor sensitivity" may be grouped under "sensor operation factors," for example. Another filtering tool was the frequency of an item's recurrence in the dataset. For example, "sensor accuracy" and "sensor scaling range" came up many times and constitute a strong need whereas the "camera serial interface" was a singleton. Eliminating recurring and similar findings was quite useful in reducing the size of the data set.
At this point, I was left with 92 unique findings. From here I continued filtering and iterating, using the techniques mentioned above, which also involved a mixture of bubble sort and merge sort algorithms. I used bubble sort so that I can iterate over the dataset, compare adjacent items, and swap them if they are in an ambiguous grouping. And a merge sort algorithm was useful because I needed to divide the sorted items into separate categories. These categories reflected what could be in the scope of TC53 work. This last method allowed me to discover things that TC53 API would need to support, things that could optionally be supported, and things that didn't fit within the scope of current TC53 work. So I came up with the following three categories:
- Must: the essential metadata that must be included in the TC53 specification
- Maybe: non-urgent, but potentially useful, metadata
- Out of Scope: metadata that was beyond the bounds of the initial TC53 sensor metadata proposal
It is worth noting that the following factors were also considered when classifying the dataset:
- the recurrence of a finding
- data accuracy
- behavioral clues from the interviews
Behavioral clues involve enthusiasm, an over-recurrence of a saying from the interviewee, or an "aha" moment when an interviewee remembers a recurring problem they solved with a quick hack but would love to find a better solution.
2. Splitting the Categories
The second phase consisted of breaking the Must and Maybe categories into concise and descriptive sets. The goal is to group the findings in a hierarchical structure. The following questions helped achieve that goal: What are the items of metadata that only the sensor knows? What items in my dataset pertain to the microcontroller or app controlling the sensor? What information is held by the entity that manages the microcontroller? And finally, what metadata items are maintained by third-party entities? Answering these questions and more, with the help of some TC53 members, resulted in a productive and conducive classification of the dataset. In the following, I briefly describe my process for answering each of those questions, finding the associated items, and naming the set of these items accordingly.
-
What does only the sensor know? This question hints at very distinctive information about the sensor. Let us name this set "sensor entity" and find any items that belong to it. Looking at my dataset, it seems that "accuracy", "scale factor" or "communication interface" are directly tied to the sensor. But in truth, those metadata are configured at the app running on the microcontroller, so they don't directly belong to this set. What about "model number", "sensor unique ID" and "the time & location of manufacture"? They seem to fit, so let us add them to the "sensor entity" set.
-
To this question "What items pertain to the microcontroller?", we have from 1. that things such as "sensor scale factor" or "accuracy" can be configured from the microcontroller using an API or a driver. Therefore, let us add them to a new set named "device entity". We know that the "procedure/algorithm" item can alter the sensor raw data at the MCU level, so let us add it to the set. The same applies to the "sampling rate" item too. Note that it is uncommon for a sensor driver to configure every single characteristic or measurement component of a sensor. In these cases, default values are used that can be looked up in a data sheet. Such default parameters belong to the "global entity" set.
-
Our next question deals with the entity, let it be a developer or a company, that manages the sensing platform (MCU and all the sensors attached to it). This set can be named as the "organization entity" and may encompass any item related to the association of the sensor, the device, and any operational constraints. For example, only this entity knows the location of the sensing platform in the field. So let us append "latitude & longitude coordinates" to the set. But locations are not necessarily geographic, so let us add "IP address" too. What about "picture of the sensor in the field", "time entry of sensor repair" and "the name of the repair engineer"? These did not occur frequently enough to merit inclusion in the final set of metadata categories.
-
At this point in the hierarchy, what items do neither the sensor, nor the device, nor the organization have access to? That can help us answer our last question. By naming this set "global entity", I can add the following items: "customer reviews of the sensor", "a reference to available drivers for that sensor", "link to the sensor datasheet" and "average local temperature".
By following the steps described above, we have been able to classify the overall dataset into two relevant categories: "Must" and "Maybe". Consequently, each category has been successfully split into four different sets/entities: sensor, device, organization, and global.
3. Parsing Summary
The following pictures summarize the results of my findings and how they are classified:
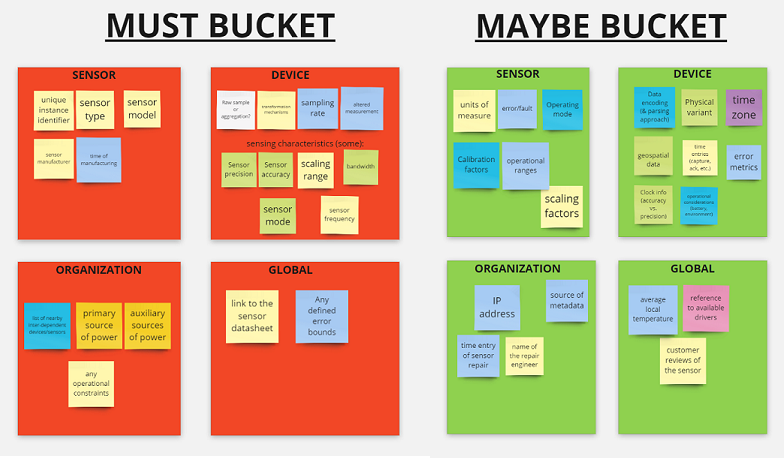
Overall, these results inform us that the API needs to allow users to query a sensor’s sensing characteristics that are configurable and whose default parameters have been changed. These findings also reveal that algorithms or filtering procedures that can transform the original raw data should be reported as device metadata. Further, the altered data itself should also be reported as "synthetic" (i.e, flagged as "altered"). A sensor should also report its model and manufacturer metadata. The following metadata may be queried if possible: error patterns, calibration parameters, and units of measure.
Before using the results for specification drafting purposes, it was crucial to find out how TC53 sensor metadata relates to any prior art. I detail this in the next section.
Prior art
With the intent of not reinventing the wheel, I have analyzed existing and similar API work. I mostly focused on the following:
- The GS1 barcodes specification that is used to generate the barcodes that uniquely identify products in stores.
- OGC SensorML (Sensor Model Language) that specifies XML encoding for describing sensors and measurement processes, usually for remote sensing.
- OGC O&M (Observations and Measurements) that defines XML schemas for sensor observations and for features involved in sampling when making observations.
- OGC SensorThings that provides JSON encoding used to interconnect sensors and sensor data over the Web
Taking the example of the GS1 barcodes specification, I discovered GS1's methods for specifying and assigning unique UPC/EPC codes to their end-users. A barcode is an encoding of 12 numeric digits representing the combination of a company GS1 prefix and a product reference number. More information on barcode encoding can be found on the GS1 website.
The most exciting part about GS1 barcodes is how GS1 stores the metadata associated with those barcodes. I believe TC53 could take inspiration from this process. When it comes to metadata storage, GS1 provides two options for inquiring about any metadata associated with a trade item.
The first option, free of charge but limited in functionality, is a distributed database called the GS1 Global Electronic Party Information Register (GEPIR). GEPIR only allows a user to check the validity of a UPC, look up a company’s information, and verify who manufactures a product.
The second option, which is a paid feature, offers tools for querying all available metadata about an item. This is called the GS1 Data Hub and can provide the following metadata: the product description, the industry, the packaging level and hierarchy, country of origin, as well as any other customer-related questions about the product and more.
OGC Web Standards provide an interoperability framework with standard interfaces and encodings for network-accessible sensors regardless of the manufacturer or proprietary aspects of any given sensor. The framework offers both JSON and XML schemas and is meant to aggregate a diverse universe of sensor metadata and data from different sources all over the internet.
The TC53 Sensor Data Provenance Specification draft faces the same issues that OGC faced: different manufacturers with different ways for querying the sensor, meaning different proprietary ways for describing a sensor. OGC solved these questions through a suite of standards, each designed to address the issues of real-time encoding of sensor data, discovery and location of sensor observations, and a standard web service interface for requesting, filtering, and retrieving sensor observations and more. There are at least seven different sensor-related OGC standards. TC53 could take inspiration from one of the OGC standards: SensorThings, because it provides JSON encoding. SensorML could be a good starting point as well.
Personal Viewpoint on TC53 Sensor Provenance API design
In the light of my research on OGC and GS1 standards, I will offer the following suggestions for TC53 sensor provenance API.
Similar to the GS1 specification, the TC53 sensor API should enable the following:
- The end user should be able to query the model and manufacturer information from the sensing platform (MCU + sensors).
- There should be a globally-unique identifier, assigned by TC53, for each device model similar to UPCs (which are assigned by GS1).
- TC53 or a third-party should provide access to a central database, on the internet, containing all sorts of sensor metadata related to TC53. The API should allow the end user to query that database and check the meaning of a particular metadata at will.
Similar to OGC SensorML and OM, the TC53 Sensor Metadata API should:
- report any procedures or transformations that might have altered the original sensor readings
- report any time when the original sensor readings might have been altered
- provide the real-world time associated with data logging
- provide a sensing framework that handles diverse sensors' sensing characteristics
My first exposure to the drafting of a standard was challenging and exciting at the same time. I had the opportunity to attend the first two meetings of drafting the sensor metadata specifications. On one hand, a downside I faced is that I didn't have much experience in drafting specifications. At such, I wasn't able to write as much as the main editors. A second downside was the challenge of representing as many need statements as possible. I'm sad to see that the needs of some of our end users are out of TC53's scope at this point in time. The good news, however, is that there is hope such needs could be addressed in the future. On the other hand, contributing to specification writing has its perks too. The specification drafting meeting gave me the opportunity to not only see how real-world standards are written but also to give my opinions and feedback for the implementation of the standards.
Even though my internship is ending, I am grateful that Moddable and MSU are allowing me to keep collaborating on the writing of the draft specification and hopefully help in the design and implementation of a reference sensor provenance API.
Conclusion
Overall, this was a very exciting summer. Working with Moddable and TC53 enabled me to sharpen fundamental skills, both technical and non-technical.
Being able to develop sensor- or IoT-based solutions to solve problems is more than a noble task. Thanks to this internship, I have developed skills for learning a new programming language, JavaScript, efficiently. On one side, I can use this language to create IoT solutions in my areas of interest (digital farming, remote sensing) and also collaborate with embedded and non-embedded application developers alike.
On the other side, the interview process enabled me to improve both my oral and written communication skills. In particular, parsing the interview results exposed me to UX design techniques that are another way of solving problems creatively.
I am thankful for all my interview participants and I am grateful to Moddable for extending the offer for further collaboration on TC53 work. I strongly believe this API will help our end users tremendously in their work when it comes to validating the accuracy of sensor data.